Hinge loss
Hinge loss is a loss function in machine learning. The hinge loss function is the following:
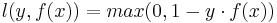
Hinge loss works well for its purposes in SVM as a classifier[1], since the more you violate the margin, the higher the penalty is. However, hinge loss is not well-suited for regression-based problems as a result of its one-sided error. Various other loss functions are more suitable for regression.
References
- ^ Rosasco, Lorenzo; Ernesto De Vito, Andrea Caponnetto, Michele Piana, Alessandro Verri (May 2004). "Are loss functions all the same?". Neural Computation 16 (5). doi:10.1162/089976604773135104. http://web.mit.edu/lrosasco/www/publications/loss.pdf. Retrieved 8 October 2011.